
别迷信开源安全:那些年我们踩过的坑与应对之策
标签: 2026-05-08 次
在早些年做技术选型的时候,我们团队在开源软件上投入了大量的时间。那时候大家普遍认为「开源 = 更安全」,毕竟代码是公开的,谁都能查看,想着漏洞肯定能早早被发现。然而,后来因为依赖包引发了生产问题,我们才惊觉这种想法大错特错。
以前我们使用一款主流的Web框架,一直跟着社区更新版本,也没专门去做安全筛查。直到有一次上线后,运维同事察觉到异常请求,经过一番排查,发现是间接依赖的一个小工具包被投毒了。这个包本身的star数不少,贡献者也很活跃,可就是有人偷偷把恶意代码塞了进去。经历这件事,我们才意识到:开源所谓的「众人审阅」,并不意味着就有人真能为你兜底。
很多团队会把开源安全寄托在「社区审查」上,实际情况却并非如此。就我们接触过的项目而言,真正有专职安全人员跟进代码审计的少得可怜。大多数贡献者都是普通开发者,他们擅长编写功能,可对于密码学、输入校验这些安全细节,不一定熟悉。比如之前我们在review一个支付相关模块时,发现有个开发者自己写了一套签名逻辑,乍看没问题,但实际上遗漏了对边界值的处理,要不是第三方安全工具扫描出来,后果简直不敢想。
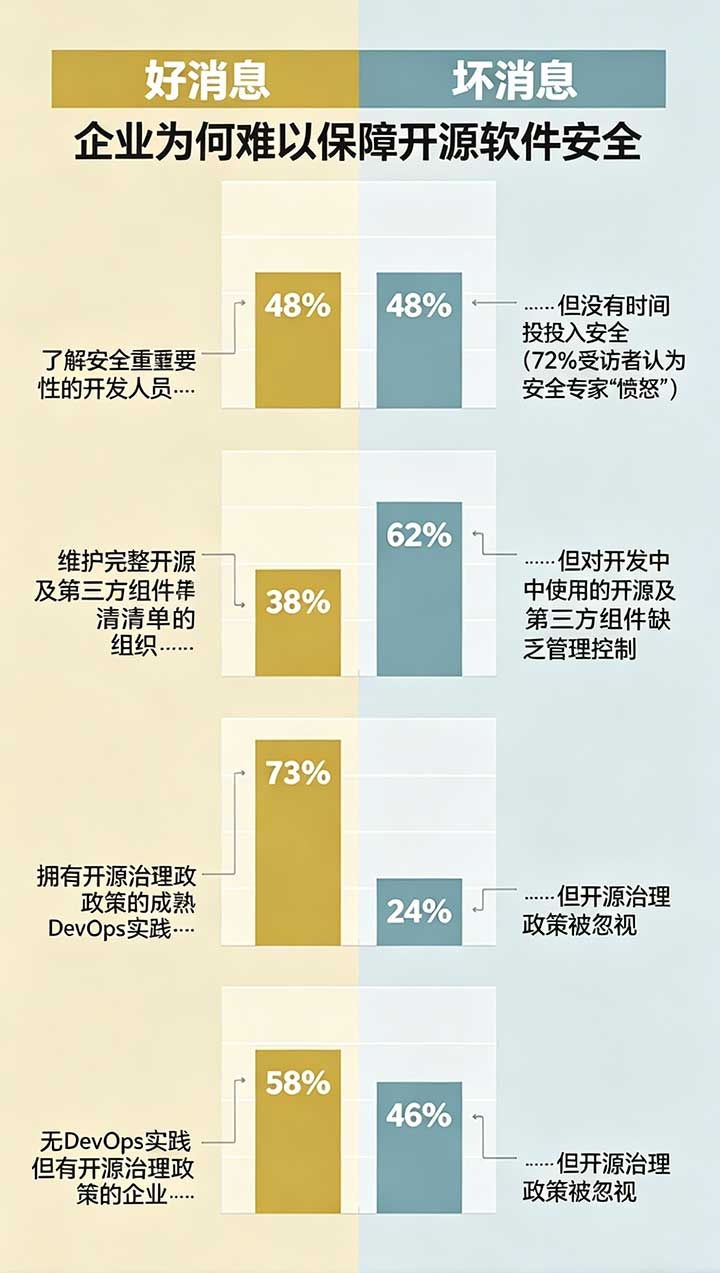
依赖管理也是个大问题。如今做开发很少有人会从零开始造轮子,npm、Maven这些仓库里的包层层嵌套。我们统计过,一个普通的Spring Boot项目,间接依赖能多达上百个。你能保证直接使用的组件没问题,但第四层、第五层的依赖,谁敢打包票说百分百干净?之前Black Duck的报告提到,九成以上的商业软件都使用了开源代码,但超过半数的企业连基本的依赖管控都没做——这可不是危言耸听,而是我们身边实实在在的现状。
后来我们也摸索出了一些切实可行的办法。首先,别把所有希望都寄托在「别人会去修复」上。现在我们团队对于核心业务所使用的开源组件,都会先进行一轮基础筛查:看看有没有已知漏洞,维护频率如何,近期有没有异常提交。不用逐行去看代码,先把风险过滤一遍。
自动化工具确实帮了大忙。在CI/CD流程中加入静态代码扫描、依赖检查,新版本发布前跑一遍,能拦截大部分低级问题。不过工具也不是万能的,像逻辑漏洞、权限绕过这类问题,还得靠人工review。我们一般会针对高风险模块(比如涉及用户数据、支付的)单独进行安全测试,不追求全覆盖,先把核心链路守好。
补丁管理也不能落下。以前总觉得「能用就不升」,后来发现很多攻击都是针对旧版本漏洞的。现在我们立下规矩:高危漏洞补丁必须在72小时内评估,能升级就升级,实在不能升级的就得添加防护规则。这工作虽然琐碎,但总比出了问题再去救火要好。
合规方面也越发重要。像GDPR这类法规,不管你在不在欧洲,只要涉及用户数据,就得按规定执行。去年我们做等保,光是梳理开源组件的license和数据处理逻辑就花了两周时间——早做准备,总比被监管部门找上门强。
开源本身确实是件好事,能节省不少开发成本,但在安全问题上绝不能偷懒。我们常说:代码公开带来了透明,但风险并不会自行消失。与其指望别人帮你盯着,不如自己多做一步。毕竟系统要是真出了事,最后承受压力的还是自己团队。





