搭建线性模型代理:困难之处与解决之道
标签: 2026-04-22 次
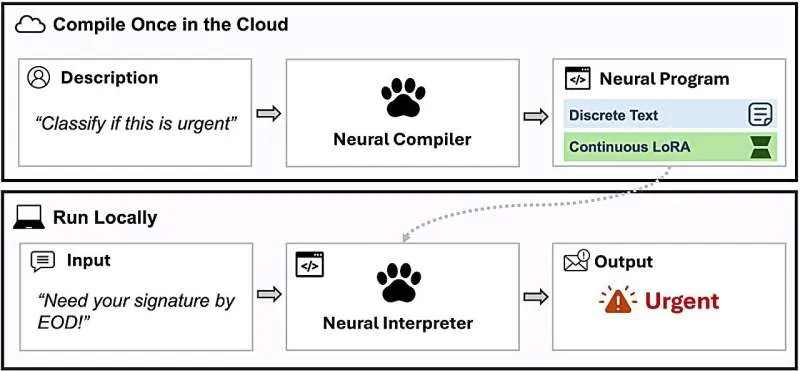
在北京心玥科技,我们把各类事务,像错误报告、用户反馈以及功能任务等,都记录在Linear里。我们已经在本地运用模型代理,不过目前存在一个问题,就是它们之间的连接需要手动完成,比如把票据上下文复制到代理中,启动对应仓库的工作树,输入计划,打开PR,再把它们和票据关联起来。为了解决这个问题,我们搭建了Huginn,这是一个集成在Linear中的模型代理。你只需委托一个工单,它就能读取上下文,确定需要更改的仓库,提出计划,等你批准(或者不批准)后,它就会执行、自我审查并打开PR。整个交互过程通过Linear内置的Agent API实现,无需切换到其他工具。而且你还能把它设置成自动模式来处理简单任务,在PR打开后请求跟进,它会以你的GitHub身份提交,这样git blame依然有效。产品方面相对容易解释,接下来本文着重探讨工程上的问题,包括遇到了什么状况、哪些让我们感到意外,以及我们原本可以做出哪些不同的决定。

将CLI代理包装为子进程
Huginn并不直接调用LLM API,而是把Claude Code和Codex作为子进程启动,它们各自有着独特的流格式、会话管理以及认证模型。这事儿说起来简单,实际操作才发现困难重重。就拿Claude Code来说,它得通过--output - format = stream - json输出JSON,但前提是要同时传递--verbose flag,而且这个flag还必须在--output - format之前。我们可是因为往生产环境发送错误的解析才发现这个问题的。还有,它的JSON内容嵌套在message.message.content下(并非message.content),这一点在任何文档里都没提到。Codex也不省心,有自己的流格式和会话模型,还会把 后一个响应写入临时文件,进程退出后你还得去读取这个文件。会话管理更是麻烦,Claude Code用--session - id启动新会话,用--resume继续已有会话。要是用户失败后点击“重新尝试”,Huginn会生成相同的确定性会话ID。可要是之前的Claude进程还没完全退出,--session - id就会失败并显示“已经在使用中”。解决办法就是双向回退:先尝试--session - id,冲突就用--resume重新试,反之亦然。现在回头看,就三行代码的事儿,但却是出了生产事故才发现的。每个提供者都有自己的失败模式,要是把提供者特定的逻辑混进工作流代码,那可就糟了。所以我们很早就搭建了一个AgentRunner接口,Claude和Codex各自都有自己的运行器、参数搭建器、输出解析器和会话处理程序。工作流引擎只和这个接口通信。要是团队里有人想试试Codex,只需要引入一个新类和一个工厂方法,工作流代码都不用改。这种抽象可不是过早设计,而是自我保护。
输出解析战争
从LLM响应里获取结构化数据,那叫一个难,而且是每次都难。下面是我们遇到的一些情况,大致按遇到的顺序排列:
- 规划时发现的仓库,执行时却找不到了,因为我们没在问题描述里持久化它们。
- Claude的结果信息覆盖了累积的计划内容,我们首个步骤次修复还导致了输出重复。
- 代理把REPOS:行放在底部而不是顶部,把我们的解析器搞坏了。
- 代理人把回购名称用**粗体**标记包起来,解析器没去掉。
- Codex把MCP工具参数当成JSON字符串发过来,而不是对象。
- Claude和Codex看到的MCP工具名称格式不一样(huginn_planning_result和mcp__huginn_workflow__huginn_planning_result)。
- 代理返回的计划只有元数据头,没有实际计划内容。
我们一开始用文本解析,让代理在首个步骤行输出REPOS: api, apps,然后用regex处理,可靠性大概80%。后来添加了一个MCP服务器,它暴露了结构化工具,huginn_planning_result能接受{ plan, repos, step_descriptions }作为类型化参数。MCP能强制规范结构,所以它正常工作的时候还挺好。但问题是MCP工具有时候对代理不可用,我们也不太明白为啥。所以,我们的代码用了三种提取策略:先调用MCP工具,然后解析文本输出, 后解析累积的预结果输出。仓库名称解析器自己处理用markdown转义的名字、尾随标点符号、repos/路径前缀和unicode艺术品。每个规范规则都能追溯到特定的生产错误。这问题没法彻底解决,只能尽量管理。每隔几周,我们就会发现代理用解析器没预料到的方式格式化输出,然后就得加个新情况处理。要是你在LLM工具上搭建编排器,可得提前考虑到这个,它不会停下来的。
会话连续性和CWD陷阱
早期每个工作流程阶段都会启动一个新的代理会话,代理得重新读取代码库、工单,从头重建上下文。这样不仅令牌消耗高,质量还下降,因为代理在阶段之间会忘掉自己之前做的决定。后来我们增加了会话连续性,用一个SQLite表把(issueId,continuityType,provider)映射到Claude/Codex会话ID。规划、实施、代码审查和PR创建都恢复同一个会话,这样代理就能记住自己计划的内容,这在它审查自己代码的时候很重要。但这暂时把PR创建搞坏了,而且根本原因还不明显。原来是Claude Code把工作目录当成会话查找键的一部分。实现阶段从 /workspaces/ENG - 485(工作区根目录)运行,可 初PR创建是从 /workspaces/ENG - 485/xinyue - api(代码库子目录)运行。不同的工作目录导致Claude解析出不同的会话,这种不匹配造成了无错误信息的隐形失败,没有错误提示,就是会话没有我们预期的上下文。解决办法是每个阶段都把工作区根目录设为CWD,然后通过提示直接对每个仓库操作(比如“从xinyue - api/目录创建一个PR”)。这虽然是个小约束,但找问题可花了不少调试时间。要是你链式调用多个Claude Code实例还依赖会话持久化,一定要保障它们的CWD完全一样。
线性标签状态机
Huginn的工作流有四种状态:IDLE → PLANNING → APPROVED → EXECUTING,我们把状态存成问题上的线性标签。这可不是我们一开始就这么做的, 初我们把状态模型成JSON存到Linear的计划字段里(这是个用于显示进度步骤的用户界面元素)。结果后来发现Linear会归档代理线程,把计划内容和我们的状态都清除了。还是标签好用,它们能存档,在问题列表里可见,你可以按huginn:executing过滤查看正在运行的内容。工程师能手动移除标签重置状态,或者添加huginn:approved跳过规划。系统每次收到webhook都会读取标签,所以手动覆盖也不需要特殊处理。在执行过程中,子阶段标签能跟踪更详细的进度,像huginn:stage:workspace - setup, huginn:stage:implementation, huginn:stage:code - review, huginn:stage:pr - creation。要是服务器执行过程中崩溃了,重启时读取这些标签就能从正确阶段恢复。恢复系统从分支名称推断工作区路径,检查磁盘上是否还存在。把外部系统的元数据用作用户可见的状态和崩溃恢复状态,听起来有点像临时拼凑的,但实际上这是整个系统里 可靠的部分之一。
99%由AI生成的代码库究竟意味着什么
Huginn的大部分代码是由AI模型代理编写的,很多还是Huginn自己写的。但没点上下文,这话容易误导人,实际工作流程是这样的。自举是由人驱动的,像选择TypeScript、Fastify、Drizzle、SQLite、标签上的状态机架构、提供者抽象模式,这些都是人的决策。智能体负责写代码,但有人在引导。基础工作完成后,循环过程如下:先编写包含用户流程、边缘情况和高影响技术决策的规格说明,让代理先写测试,然后审查测试案例(这可是花了我们大部分审查时间),接着让代理实现,再发布,之后手动测试,出现问题就修复。我们不会逐行审查生成的代码,主要审查规格和测试。能让这一切顺利进行还不出乱子,靠的就是DTU:数字双宇宙。对于Huginn依赖的每个外部服务,我们都搭建了一个行为副本,实现真实的API接口,但在内存里运行。我们的Linear DTU是个Go服务器,实现了Linear的GraphQL API。测试用真实的@linear/sdk和这个假后端交互,能生成问题、触发webhook交付、验证标签是否设置、检查活动是否发出。GitHub DTU负责仓库创建、分支管理和PR创建。KMS DTU用内存中的密钥进行信封加密。每个DTU都在Docker容器里运行。集成测试用Testcontainers启动完整堆栈:Huginn及其所有依赖项。测试场景在Linear twin里生成一个问题,触发webhook,然后断言Huginn产生了正确的标签、活动和PR。Huginn还能调试自身生产问题,它能SSH到VM里,读取日志,关联错误,编写修复程序。大多数部署后的问题都是这么解决的。AGENTS.md文件积累了每次事故的教训,所以代理随着时间推移,在遵循项目规范方面越来越熟练。这一切能实现,全靠坚固的测试基础设施,要是没有DTUs,这么大规模使用AI生成的代码可太冒险了。
什么还是有问题
输出解析,就像上面说的,是个没完没了的事儿,永远搞不完。BYOK证书系统也还有待完善。OAuth令牌得给每个用户把~/.claude复制到临时目录,每个临时HOME目录都包含重复的包管理器缓存(.npm,.cache,.nvm)。在我们的虚拟机上,五个用户就占了大概25GB空间,后来才发现这个问题。解决办法是用符号链接和cron作业,但整个按用户划分HOME的方法感觉还是得重新想想。紧密的迭代工作还是很难,要是一个任务需要像跟另一个开发人员配对讨论一小时那样反复交流,Huginn就不太适合,用本地代理或者在创建工单前先在规格上迭代会更有效。涉及多个文件,需要细致架构判断的大任务也会遇到瓶颈,规划阶段有点用,但通过工单描述能传达的信息有限。
那一刻它起作用了
首个步骤次,一个tickets从“在Linear中创建”直接变成“PR创建”,期间没人打开IDE或者克隆仓库,就是那一刻。整个工作流程在Linear的代理用户界面里清晰可见:想法出现,计划生成,代码编写,PR创建。从那之后,我们的缺陷和用户反馈积压问题明显减少。这不是说代理比人更会修复缺陷,而是因为启动成本降到了零。提交工单,分配,继续就好。