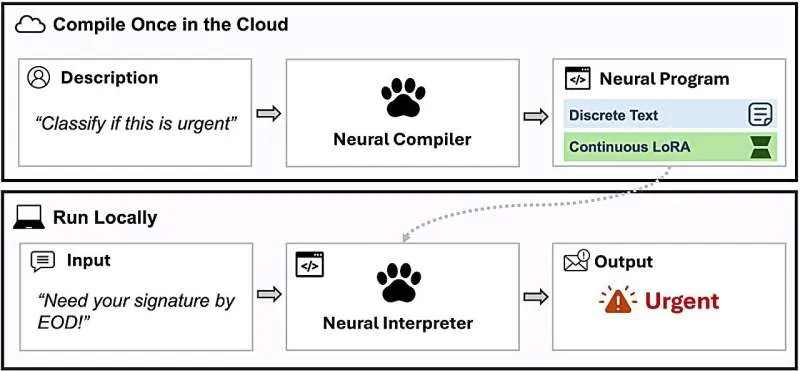
13个软件系统性能指标及测量方法
标签: 软件系统开发 2026-04-17 次
说实话,做开发这些年,我算是摸透了:系统稳不稳,全看你抓的指标靠不靠谱。指标这东西就跟体检报告似的,哪项高哪项低,一眼就能看出哪儿“亚健康”了。但新手 容易栽的坑就是——要么盯着一堆没用的指标瞎忙活,要么把那些听起来特“高大上”的指标当救命稻草,结果越监控越懵圈。
今天就跟大伙儿唠唠我这些年用废三套监控系统、踩过无数坑后攒下的“土办法”性能指标观。那些说“必须监控XX项”的都是纸上谈兵,我踩了这么多坑,就认一个理:抓核心的、能解决问题的,比堆一堆没用的强。
说到CPU啊,这玩意儿就像系统的心跳,得时刻留意着。新手 容易犯的错就是只看平均值,觉得“60%挺安全”,结果有次上线新功能,监控里CPU曲线“唰”一下从40%窜到85%,用户直接吐槽“点个按钮跟等外卖似的,转半天圈”。后来才明白:峰值比均值重要一百倍!长期超过70%就得捏把汗了——要么是代码写了死循环(我同事有次写递归没设终止条件,直接干成无限循环,CPU瞬间飙到100,服务器差点没冒烟),要么是多线程抢资源抢到“打架”。
你得记住:CPU报警不是让你立刻扩容,是先去查“谁在疯狂吃CPU”。上周刚帮隔壁组定位个问题,他们CPU飙到90%, 后发现是个日志打印语句没加开关,疯狂刷磁盘把CPU给拖累了,你说逗不逗?

内存这玩意儿比CPU还阴险,表面看着风平浪静,背地里偷偷给你捅刀子。我踩过三种典型的坑:
一种是内存虚高,比如缓存没设上限。有次大促,有人把全量商品数据往Redis里塞,内存“砰”一下就爆了,当时监控告警响得跟过年放鞭炮似的。
另一种更坑,内存泄漏。 经典的就是“用完不释放”,有次Java服务跑了半个月,内存从2G慢慢涨到8G, 后“啪”一下OOM崩了,查了三天才发现是线程池忘了关,你说气人不气人?
还有种叫“内存颠簸”,就是虚拟内存不够时,系统在内存和磁盘间来回倒腾数据,慢得跟蜗牛爬似的。那次排查,我用free-m一看,swap用了5G,当场血压就上来了。
追踪内存别光看使用率,页面错误数(PageFault)和磁盘访问时间才是关键——这俩一飙,说明内存是真不够用了。
再说说请求相关的指标,别被那些“数字游戏”忽悠了。“每分钟请求数”和“每请求字节数”常放一块说,但新手容易只看前者。比如有个API每分钟能扛1000请求,可每请求传10MB数据,带宽直接被打满,实际吞吐量还不如每分钟500请求但每请求1MB的接口。
我之前就犯过傻:给图片上传接口设“每分钟请求数”阈值,结果用户传高清图,字节数超标导致超时,报警愣是没触发。后来学乖了:请求数和字节数得绑一块看,就像看车速不能只看里程表,还得看载重。
延迟和Apdex这俩,简直是用户体验的“照妖镜”。延迟听着专业,说白了就是“用户点鼠标到你系统回应的时间差”。别信“平均延迟”,得看P95/P99延迟——比如P99延迟500ms,意思是100个请求里 慢的1个要等半秒。有次产品说“平均延迟200ms挺好”,结果用户投诉“偶尔卡10秒”,一查才知道P99延迟飙到10秒了——长尾请求才是用户体验的杀手啊!
Apdex分数我首个步骤次用就闹笑话。按教程设阈值T=5秒,结果用户明明抱怨“慢死了”,分数还0.9(满分1)。后来才懂:阈值得按业务调。电商下单设5秒合理,后台报表设20秒也没事。我们现在公式是:Apdex我是这么算的:满意的请求数,加上能容忍的请求数的一半,再除以总请求数,能容忍的就是响应时间不超4倍阈值的,说白了就是看用户到底爽不爽。上次大促算出来0.82,就知道得赶紧优化那批12秒以上的慢请求了。
错误率这指标,新手常只看“HTTP错误百分比”,结果漏了更隐蔽的坑。比如“抛出异常”数突然涨了,可能是代码里偷偷抛了未捕获的异常;“记录异常”数涨了,可能是日志级别设太低,把正常警告当错误处理了。
有次凌晨三点,错误率从0.1%“噌”一下跳到15%,我们一边查日志一边冒冷汗, 后发现是第三方接口HTTPS证书过期了——这种“非代码bug” 容易被忽略。记住:错误率得结合“错误类型”看,4xx是用户问题(比如传错参数),5xx才是系统问题,得立刻修。
正常运行时间(Uptime)这事儿也有意思,都说要高可用,追99.9%Uptime,但你算过吗?99.9%意味着一年允许宕机8.76小时。电商大促时,宕机10分钟可能就丢百万订单——这时候“99.9%”就是个笑话。
我们现在的做法是按业务优先级分级监控:核心交易链路要求99.99%(年宕机52分钟),后台报表允许99.5%(年宕机43小时)。别盲目追高数字,贴合业务才是王道。
数据库查询通常是系统的“命门”,别等崩了才查慢SQL。以前我觉得“数据库快就行”,直到有次大促,慢查询日志里躺着个扫全表的语句(SELECT*FROMordersWHEREcreate_time>'2023-01-01'),没加索引,直接把CPU干到100,数据库卡了半小时,用户全跑光了。
后来我们定了规矩:每天早会先看慢查询TOP10,索引缺失、全表扫描、返回冗余字段(比如查用户列表非要带密码哈希),全是重点盯防对象。对了,还有“连接数”——别以为连接池设大点没事,Postgres默认较大连接数100,我们曾因连接泄露(服务重启没释放连接),把数据库连崩了3次,运维同学差点把我桌子掀了。
吞吐量(RPS/TPS)常被吹成“性能天花板”,但实际得看“稳定吞吐量”。比如某接口压测能扛1万TPS,但持续10分钟后CPU就上80%,这1万TPS就是“虚的”。
我们更关注“吞吐量-延迟曲线”:当吞吐量涨到某个点,延迟突然翻倍,那就是瓶颈了。有次优化支付接口,从500TPS涨到2000TPS,延迟从200ms涨到800ms,查了半天才发现是数据库连接池太小,加了个连接池监控才稳住。
做Java的都懂,GC一停,系统就卡。以前我觉得“GC时间占比低就行”,结果有次服务频繁FullGC,每次停2秒,用户点按钮就卡一下,体验差到爆。后来才关注“GC暂停时间”和“对象创建率”——创建率越高,GC越频繁。我们把大对象(比如一次查1万条数据)拆成小批量,对象创建率降了一半,GC暂停从2秒缩到0.5秒,用户终于不骂了。
记住:GC指标别只看“吞吐量”,“暂停时间”才是用户体验的关键。
API作为系统的“脸”,得额外盯紧“使用次数”“请求延迟”“请求/响应大小”。有次开放平台API被恶意调用,请求大小从1KB涨到10KB,带宽直接打满,其他正常请求全超时。后来加了“请求大小阈值”报警,才挡住这波攻击。
还有“使用次数”,别以为“调用多=受欢迎”,可能是代码里重复调用了(比如前端没做防抖,疯狂点提交按钮),这种“无效调用” 浪费资源,得揪出来。
流量波动这事儿也得防着。平时看着平稳,大促一来能涨10倍。我们吃过亏:有次没监控“请求率”,大促前没扩容,结果流量峰值时响应延迟从200ms涨到5秒,用户全跑光了,老板脸都绿了。
现在我们的做法:把“请求率”和“并发用户数”绑一块看,用历史数据画“流量曲线”,提前3天预判峰值,该扩容扩容,该限流限流(比如非核心接口降级)。
我现在早不搞花里胡哨的监控面板了,踩了三次系统崩溃的坑后,就留8个核心指标,够用还不慌,比堆一百个指标强多了。我现在监控面板就留了8个:CPU/内存峰值、P99延迟、错误率(分5xx/4xx)、数据库慢查询数、GC暂停时间、API请求率、Uptime、用户满意度(用Apdex简化版)。
别信那些“必须监控XX项”的教条,你在实战中踩过的坑、用废的报警规则,比任何“出众实践”都管用。毕竟,系统是你写的,用户是你服务的,指标得为你自己“量身定制”——这才是监控的价值,你说对吧?