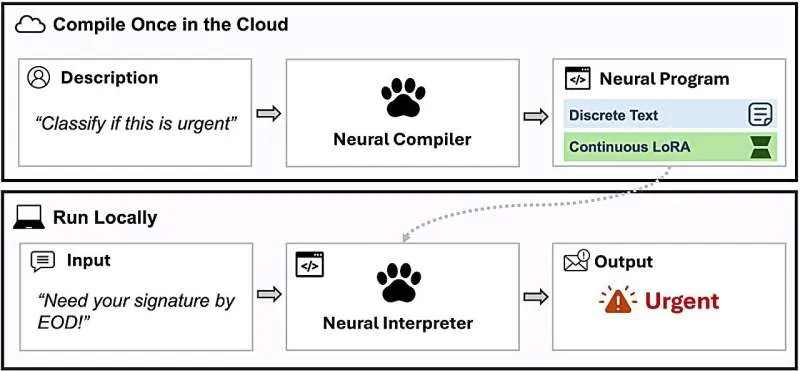
你的微服务不可扩展?其实是数据库在“哭”
标签: 微服务架构 2026-02-27 次
当初在管理系统项目里把单体拆成微服务,我们组那帮人差点没开庆功会。
画架构图时,我拿Visio拉了十几个带圆角的框,箭头标得比地铁线路图还细,旁边实习生还开玩笑:“咱这图挂工位,跟Netflix工程师墙上的海报似的。”那时候觉得,微服务嘛,不就是把大泥球掰成小块,各自跑各自的,多清爽。
结果生产流量冲进来那天,我盯着监控屏幕,手心全是汗。

Kubernetes的自动扩缩容确实灵,Pod从3个飙到30个,CPU利用率稳稳卡在60%,看着特漂亮。可数据库那边——Postgres的连接数曲线跟坐了火箭似的,直接从200蹦到5000,然后“啪”一下,所有查询全超时。系统没崩,但用户反馈“点按钮转圈比等红绿灯还久”,我们这才慌了神。
一开始全在瞎猜。
有人拍桌子:“肯定是连接池配小了!调大点!” 我连夜改配置,从100调到500,结果半小时后连接数又满了。
有人嘀咕:“Postgres这玩意儿,天生就不适合高并发,早说换MongoDB了。” 可我们数据关系复杂,哪是说换就换的。
离谱的是,有个哥们非说“K8s节点不够”,申请加机器,加完发现数据库还是喘粗气。
直到有天凌晨三点,我蹲在服务器前查慢查询日志,突然反应过来:我们压根没拆“服务”,只拆了“代码”,数据还攥在一块儿呢。
那会儿的“微服务”,其实是个带网线的分布式单体
我们当时干的事儿,现在想来特傻:把原来一个单体拆成12个服务,每个服务都直连同一个Postgres库,美其名曰“数据集中管理”。
结果呢?每个服务能独立扩Pod,可所有流量——读也好写也罢,全往一个库里灌。就像12条小溪汇成一条河,河床没拓宽,水越流越急,不决堤才怪。
开始只是延迟慢慢涨。
服务A加了个“查用户 近订单”的接口,多了3个联表查询;服务B为了报表方便,偷偷加了个“JOIN三张表”的逻辑;服务C更绝,每5秒轮询一次库存状态,说“怕超卖”。
这些改动单看都没问题,合起来却让数据库成了“公共受气包”:连接池被占满,行锁排长队,读副本永远追不上写操作。监控图上,数据库CPU飙到90%的时候,服务延迟还在“正常范围”——因为它只算自己的处理时间,不管数据库等多久。
“加缓存”治标不治本,像给发烧的人贴退热贴
当时团队里有人提议:“上Redis呗,读请求走缓存,数据库不就轻松了?”
我们真干了。搭了Redis集群,给热点数据设了TTL,一开始确实见效,响应时间从800ms降到200ms。可没俩月,新问题来了:
• 写操作还是怼数据库,库存扣减和订单创建冲突时,缓存和库里数据对不上,用户投诉“刚付款就显示没货”;
• 缓存失效策略全靠拍脑袋,有的设5分钟,有的设1小时,半夜经常“缓存雪崩”,数据库又被打回原形;
• 烦的是排查问题,得同时看服务日志、Redis日志、数据库日志,跟破案似的。
后来才懂,缓存是止痛药,不是消炎药。数据库那儿的“共享数据”病根不除,吃多少药都没用。
真正的坑:我们以为“拆了服务”,其实“数据还绑在一起”
有天跟CTO复盘,他一句话点醒我:“你们这不叫微服务,叫‘共享数据库的多进程程序’。”
对啊!当服务A改了用户表的地址,服务B读的时候可能拿到旧数据;当服务C和用户服务同时改同一条订单记录,数据库只能串行处理,锁一争用,所有服务都得等着。
我们以为“独立部署”就是微服务,却忘了数据不独立,服务永远独立不了。就像合租的几户人家,门是分开的,但厨房和卫生间共用,一个人霸占水槽,其他人照样没法做饭。
后来怎么爬出来的?全是试错试出来的笨办法
那半年我们踩的坑,现在说起来都臊得慌:
• 试过“加数据库实例”,主从复制搞了3套,结果跨库JOIN更麻烦,维护成本翻倍;
• 试过“优化查询”,把慢SQL重写一遍,索引加了几十个,可流量再涨还是扛不住;
• 甚至想过“回归单体”,被老板骂“折腾半年白干了”。
直到逼急了,硬着头皮做了几件事:
1. 先把“数据是谁的”钉死
开了三天会,把每个服务的“数据领地”划清楚:用户信息归用户服务,订单归订单服务,库存归库存服务。别的部门要用数据?要么调API(比如订单服务调用户服务查收货地址),要么订阅事件(比如库存扣减后发个消息,订单服务更新状态)。
狠的是定死“禁止跨服务JOIN”,谁敢在代码里写SELECT * FROM user, order WHERE...,直接在群里@他改。
2. 把“同步等结果”改成“异步等通知”
以前下单要同时调库存、支付、物流,全同步等返回,一个环节卡壳全完蛋。后来改成:下单发个“订单创建”事件,库存、支付、物流各自监听,做完了发“完成”事件, 后汇总状态。
刚开始总担心“数据不一致”,后来发现90%的场景不需要“立刻一致”——用户下单后,晚两秒看到物流信息,总比整个系统卡死强。
3. 每次加功能先问:“这对数据库压力多大?”
以前评审需求,大家聊“用户体验”“开发效率”,现在必加一句:“这个接口会增加多少查询?写操作频率多少?会不会和其他服务抢数据?”
有次产品提“实时统计销量”,我们算了下要扫全表,直接否了,改成“每小时跑批出报表”,数据库终于松了口气。
现在回头看:不是微服务不行,是我们把“简单”想复杂了
这两年跟同行聊天,发现踩同样坑的团队不少。大家总以为“微服务=解耦=好扩展”,却忘了解耦的核心是数据独立,不是代码独立。
数据库就像地基,你把房子拆成几间卧室,地基还是一块。地基不加固,卧室越多,塌得越快。
现在我带新人,首个步骤句话就说:“别急着拆服务,先画张‘数据地图’,看看哪些数据是‘一家人’,别硬拆散。”
毕竟,能让系统扛住流量的,从来不是“微服务”这三个字,是那些笨办法:划清边界、少走捷径、承认“数据库不是万能的”。
要是哪天你发现微服务越拆越卡,别光盯着服务数量——去翻翻数据库日志,看看是不是又有哪个服务在“偷偷”连你的库。那多半是数据库在哭:“你们拆家归拆家,别老让我一个人扛啊!”